Prompt Test Lab
A/B test prompts across LLM models and deploy winners from the same UI.
The Problem
I wanted to optimize prompts for Atomize News, but the workflow was fragmented. Testing meant manually switching between OpenAI Playground, Claude Console, and Groq, then copying results into spreadsheets to compare outputs. Deploying a winner required updating environment variables and redeploying the entire app. There was no way to roll back bad prompts or track which version was running in production.
Why It Matters
Production prompts affect user experience directly. A poorly tuned summarization prompt might truncate important context. An inefficient prompt costs more per API call. Without proper testing infrastructure, teams either skip A/B testing entirely or build one-off scripts that don’t scale. The gap between experimentation and deployment slows iteration velocity.
What I Built
Prompt Test Lab runs real-time A/B/C tests across OpenAI, Anthropic, and Groq from a single interface. You configure test cases with sample inputs, create prompt variants, and execute all combinations in parallel. The dashboard shows output quality side by side, with cost delta analysis quantifying the financial impact of switching models or rewriting prompts. When a variant wins, you deploy it with blue-green or canary strategies. Rollbacks take one click.
The architecture uses Next.js 15 edge routes for sub-3s cold starts with only 5 direct production dependencies. LangSmith integration provides distributed tracing for debugging prompt chains. Sentry captures runtime errors. Multi-tenant auth uses GitHub OAuth and Resend magic links. The monorepo splits packages/api (edge functions), packages/web (React UI), packages/shared (schemas), and packages/sdk (client library).
I realized halfway through building this for Atomize News that it solved a general problem. Every team using LLMs needs prompt versioning, A/B testing, and deployment management. Extracting it as a standalone tool made more sense than embedding it in a news aggregator.
Dashboard and Configuration
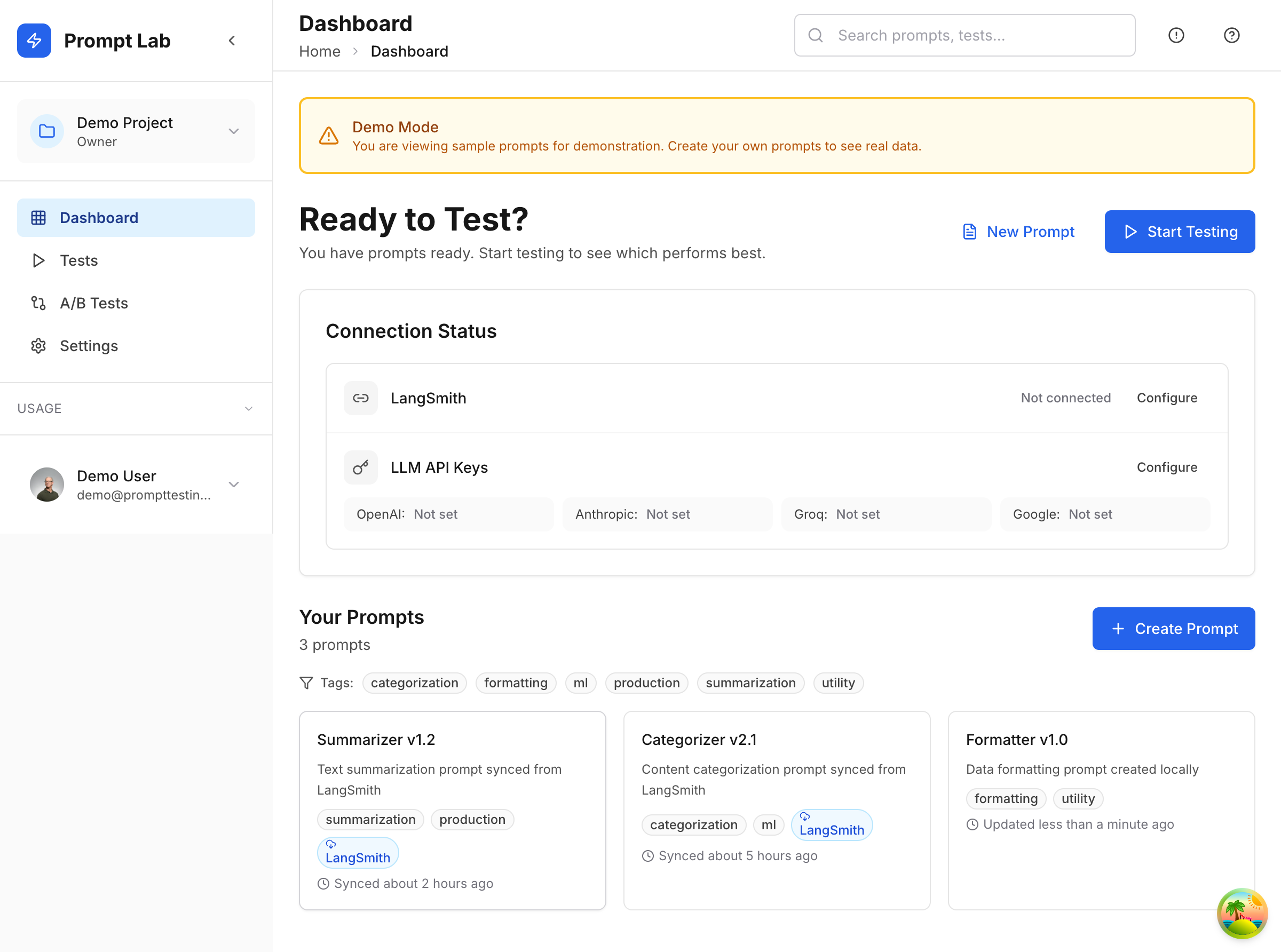
The main dashboard surfaces active prompts with tags, LangSmith connection status, and configured LLM API keys. Each prompt card shows recent test history and current deployment status.
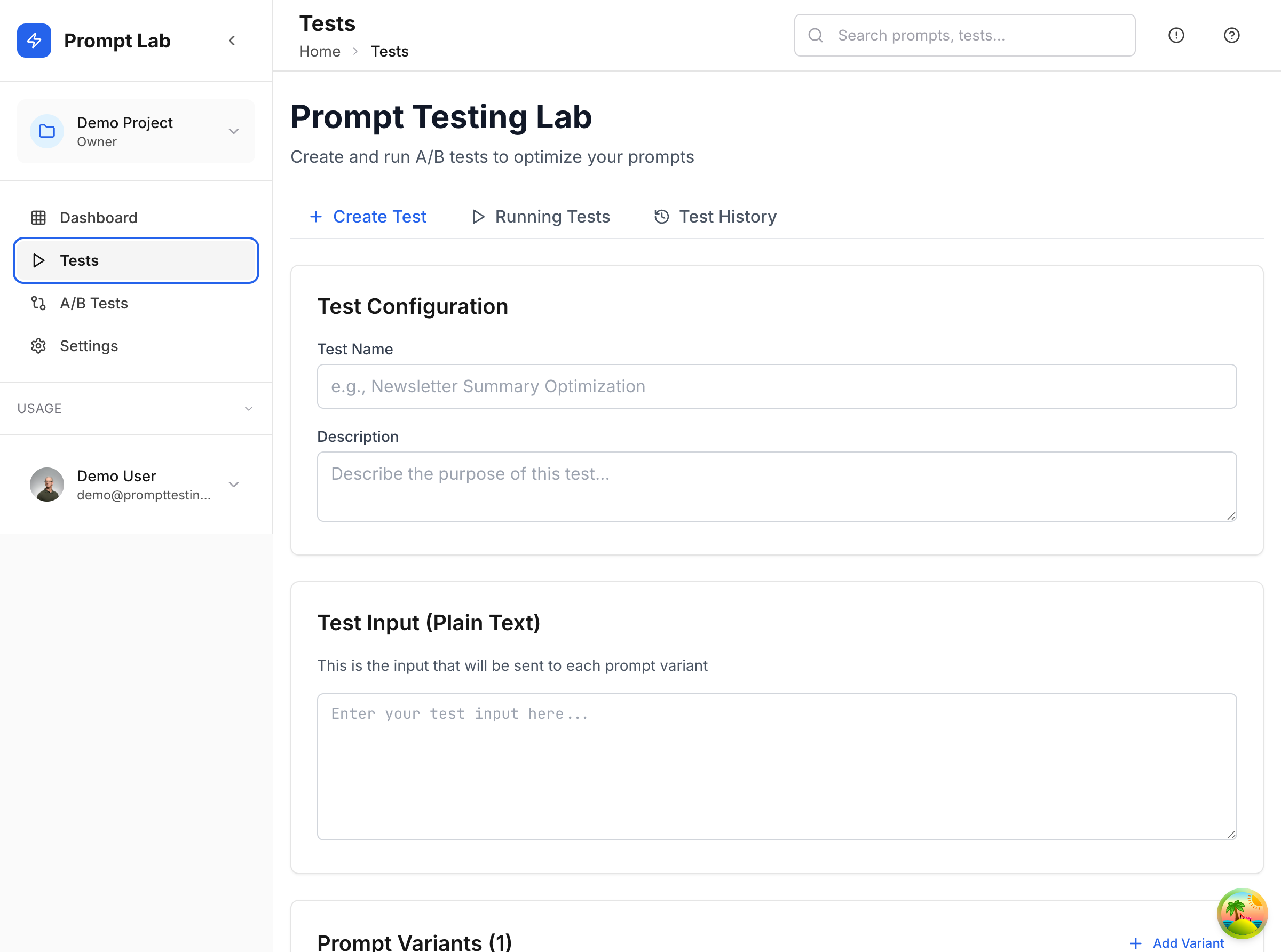
Test configuration lets you define test cases with plain text inputs and multiple prompt variants. The UI shows which models will run for each variant, making resource planning explicit before execution.
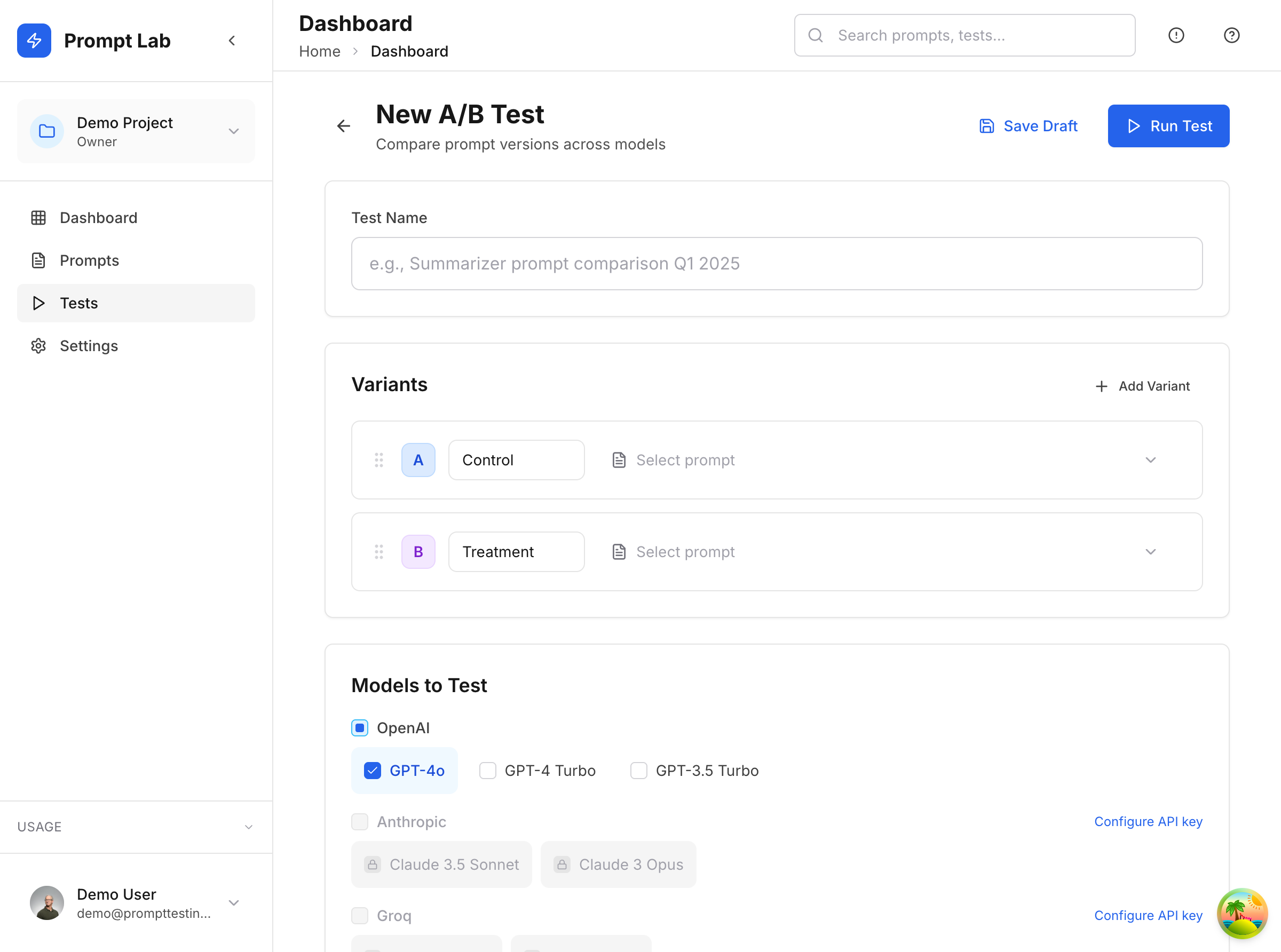
A/B Testing Interface
The A/B test creator handles variant naming (Control, Treatment), model selection (GPT-4o, Claude Sonnet, Groq Llama), and temperature tuning. Tests run in parallel across all selected models, streaming results back to the UI as they complete. Cost estimates appear before execution so you know the spend upfront.
Deployment Strategies
Blue-green deployments route 100% of traffic to the new prompt after validation. Canary deployments gradually shift traffic (10%, 25%, 50%, 100%) while monitoring error rates and latency. If metrics degrade, automatic rollback reverts to the previous stable version. Deployment history stores all versions with timestamps, cost deltas, and the reason for each change.
Impact Analysis
Cost delta analysis compares prompt versions by calculating token usage differences and multiplying by model pricing. A verbose GPT-4 prompt might cost $0.12 per request while a tightened Claude Haiku version costs $0.03, a 75% reduction. The dashboard highlights these savings across projected monthly volume, turning prompt optimization into measurable ROI.
Technical Decisions
Edge-first architecture keeps cold starts under 3 seconds even for users in Asia-Pacific hitting US-based functions. Prisma handles multi-tenant data isolation with row-level security policies in Supabase. The shared package exports Zod schemas used by both API validation and frontend form generation, eliminating schema drift.
LangSmith tracing required custom instrumentation because Next.js 15 edge runtime doesn’t support Node.js streams. I implemented a lightweight tracer that batches spans and sends them async after the response completes, keeping latency impact under 20ms.
The SDK package lets external apps trigger tests programmatically. CI pipelines can run prompt regression tests on every commit, failing builds if output quality drops below a threshold. This closes the loop between code changes and prompt behavior.