Atomize News: Intelligent Search
AI-powered tech news aggregation with semantic search, trend detection, and executive insights.
Overview
The Problem
Product and Strategy executives face a firehose of tech news. Current tools don’t filtering out noteworthy events from noise. RSS readers deliver a raw firehose with no signal filtering. News aggregators lack semantic understanding.
The Solution
A platform that gives you the news you want from sources you trust and tracks changes over time.
Initial Hurdle: I wanted to build a dashboard to track tech news but vibe coding tools didn’t scale. I couldn’t create the right filtering algorithm, search, or navigation structure. This led me to move to Cursor and Claude Code where I could define my architecture and directly edit code.
What I Built
A platform that turns tech news into exec-ready intelligence through hybrid search, parallel AI processing, and knowledge graph relationships.
The system is built on a Retrieval-Augmented Generation (RAG) pattern but enhanced with a “Fact-First” architecture. Instead of feeding raw search results directly to an LLM, the system first structures the data into a “Knowledge Graph” of entities and timelines, ensuring the final output is grounded in verified events.
Key Components:
- Ingestion Engine: A parallel scraper using BullMQ workers to ingest and normalize thousands of articles from RSS and HTML sources.
- Vector Database: PostgreSQL + pgvector equipped with HNSW indexing for ultra-fast (5-20x speedup) semantic similarity search.
- Knowledge Graph: A structured map of entity relationships (e.g., “OpenAI” owns “ChatGPT”) used to ground AI reasoning in verified facts.
- Orchestrator: A smart query router that dynamically switches between Vector (semantic) and Keyword search based on user intent.
- Trend Clustering: A two-stage algorithm that groups articles into specific Events and aggregates them into broader Industry Trends.
- Fact-Checked RAG: A synthesis pipeline that feeds verified timelines into GPT-5-nano to generate “Key Insight” summaries without hallucinations.
- Semantic Knowledge Store: A dual-layer database using PostgreSQL + pgvector to store both AI embeddings and a structured Knowledge Graph of entity relationships.
AI Search
“Intelligent Search” system, designed for high-precision, fact-based answers using a multi-model AI pipeline.
Key Insights: LLM Synthesis Engine
Approach: Retrieval-Augmented Generation (RAG) with Fact-Checking.
Rationale: This “Fact-First” RAG approach solves the hallucination problem common in LLM summaries. By forcing the model to “read” the timeline it just computed, the resulting Key Insight is grounded in verified data points rather than generic LLM training data.
Architecture:
- Retrieval. The system first performs a “Hybrid Search” (Vector + Keyword) to fetch the top relevant articles (up to 50-200 candidates).
- Fact Extraction (Timeline Construction). Before generating an insight, the system extracts concrete “Timeline Events” from the retrieved articles. This creates a ground-truth layer of facts (e.g., “Accenture layoffs,” “Mondelez investment”).
- Synthesized Generation. The gpt-5-nano model is prompted with both the TIMELINE events and the SUPPORTING ARTICLES.
Constraint Enforcement. The prompt explicitly instructs the model to base the insight on the timeline and cite specific entities. It must also output a JSON validation report tracking which articles were used vs. ignored and why.

Related News: Clustering & Hybrid Search
Approach: Parallel Hybrid Search with Cluster Boosting.
Architecture:
- Vector Search (70% Weight): Uses pgvector (OpenAI embeddings) to find conceptually similar articles (e.g., searching “AI regulation” finds articles about “tech policy laws”).
- Keyword Search (30% Weight): Uses PostgreSQL full-text search to ensure exact matches for specific entities (e.g., “Sam Altman”) aren’t missed.
- Cluster Boosting: If a user’s query maps to an existing “Trending Cluster” (pre-computed group of articles), the system injects articles from that cluster into the results.
- Blending: Results from Vector, Keyword, and Clusters are blended using a weighted ranking algorithm to produce the final “Related News” list.
- Rationale: Pure vector search often misses specific proper nouns, while pure keyword search misses context. A hybrid approach ensures high recall (catching everything relevant) and high precision (ranking exact matches first).

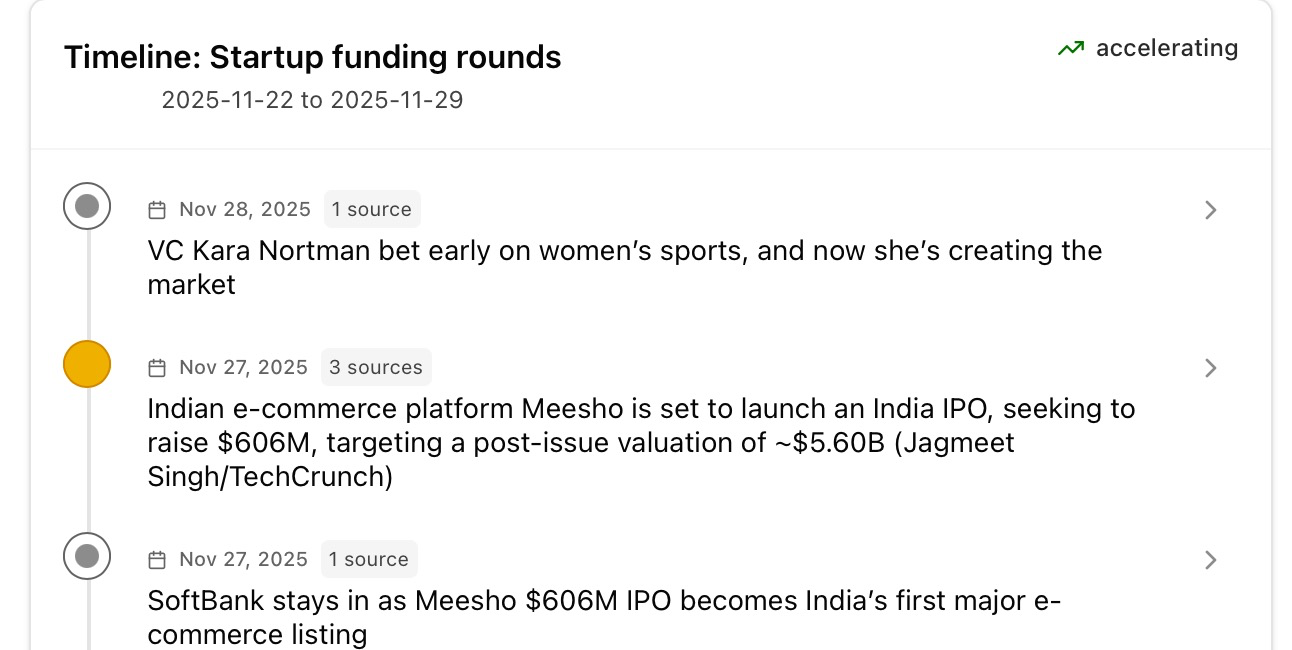
Timeline: Tracking Temporal Trends
Approach: Theme-Based Grouping with Deduplication.
Architecture:
- Extraction: The system scans the retrieved articles and extracts key events (dates + descriptions).
- Filtering: It filters out “spam” signals (promotional content, short snippets).
- Grouping: Instead of just listing events chronologically, it groups them by Theme first. This avoids a messy list of disconnected dates.
- Display: The frontend renders these as a chronological sequence of significant events, often acting as the “source of truth” for the Key Insight.
- Rationale: Timelines provide immediate temporal context that a simple list of links lacks. It allows users to see the evolution of a story (e.g., “Announcement” -> “Launch” -> “Review”) at a glance.
Sources: LLM Grounding
Approach: Source-Aware Retrieval & Filtering.
Architecture:
- Indexing: Every article is indexed with its source metadata (Publisher Name, Credibility Score).
- Query Time:
- Anonymous Users: Search across all active sources.
- Logged-in Users: Can apply a “Curated Sources” filter (stored in user preferences) to restrict results to high-quality or specific publishers. (feature turned off for logged-in users)
- Result Display: The UI explicitly shows the source count (e.g., “5 sources reported this”) for clustered events to indicate consensus or viral magnitude.
- Rationale: In the era of fake news, provenance is key. By surfacing the diversity of sources (e.g., “Reported by TechCrunch, The Verge, and 3 others”), the system builds trust and allows users to verify facts across multiple independent publishers.

LLM Models
Here is the specific model breakdown for each part of the Intelligent Search pipeline, verified against the codebase:
1. Embeddings (Vector Search)
- Model: text-embedding-3-small (OpenAI)
- Usage: Used in EmbeddingService and BatchEmbeddingService to generate 1536-dimensional vectors for all ingested articles and incoming user queries.
- Rationale: Code comments indicate this was chosen as an upgrade over ada-002 for being “5x cheaper” while offering “better accuracy.”
2. Key Insights & Synthesis
- Model: gpt-5-nano (OpenAI)
- Usage: Explicitly called in app/api/intelligent-search/summary/route.ts to generate the synthesis pyramid (Key Insight + Supporting Points).
- Rationale: Selected for speed and cost-efficiency (“fast, optimized for summarization”) while maintaining enough reasoning capability to follow strict fact-checking instructions.
3. Entity & Relationship Extraction
- Model: gpt-5-nano (OpenAI)
- Usage: Used in ExtractionService and HybridExtractor to identify people, companies, and their relationships from raw text.
- Rationale: Configured with a low temperature (0.1) for consistent, structured JSON output. gpt-4o-mini strikes the balance between entity recognition accuracy and high-volume processing cost.
4. Trend Classification & Event Summaries
- Model: llama-3.3-70b-versatile (Groq)
- Usage: Used in IntelligentQueryEngine for generating event summaries and in UnifiedTrendDetectorService for classifying clusters (Single Entity vs. Industry Trend).
- Rationale: Groq’s Llama-3.3 inference speed is leveraged here for near-real-time processing of large text blocks when summarizing events or classifying trends.
5. Query Intent & Routing
- Model: Rule-Based / Heuristic (Primary) with gpt-5-nano (Simple Queries)
- Usage: The OptimizedQueryEngine uses a ComplexityDetector to classify queries.
- Simple/Navigational: Routed to gpt-5-nano (or skipped if purely keyword-based).
- Complex/Analytical: Routed to higher-tier models like gpt-5-mini or full gpt-5 (if configured).
-
Rationale: Most user queries are simple keywords; using a heuristic router prevents wasting expensive LLM calls on trivial searches.