Atomize AI: Research Intelligence
Multi-source AI research aggregator pulling from arXiv, Anthropic, and OpenAI with knowledge graph extraction.
Recorded with the Spectra plugin
The Problem
I wanted to track AI research across arXiv, Anthropic, and OpenAI, but existing tools either cost too much or didn’t connect related findings. Atomize AI evolved from Atomize News, which focused on RSS feeds and general tech aggregation. The shift to academic and corporate research sources required deeper synthesis capabilities. I needed entity extraction that understood directional relationships, like distinguishing “Google acquired DeepMind” from “DeepMind acquired Google.” I also wanted cost-efficient LLM inference without sacrificing quality.
What I Built
Atomize AI aggregates academic and corporate AI research, extracts entities with grammatical verification, and builds a knowledge graph with confidence-scored relationships. The progressive pyramid synthesizes findings across hierarchical levels while maintaining citation integrity. Multi-model routing balances cost and quality, and observability tooling ensures reliability. It transforms scattered research into connected intelligence.
Multi-Model Architecture with Groq LPU
I built a 10-model routing system across Groq and OpenAI that selects models based on content complexity. Groq’s Language Processing Units deliver 76% cost savings compared to OpenAI-only inference while maintaining quality for straightforward summarization and entity extraction tasks. OpenAI handles nuanced analysis requiring deeper reasoning. This hybrid approach processes research papers, extracts entities with confidence scores, and builds a knowledge graph that tracks relationships between concepts, organizations, and researchers across sources.
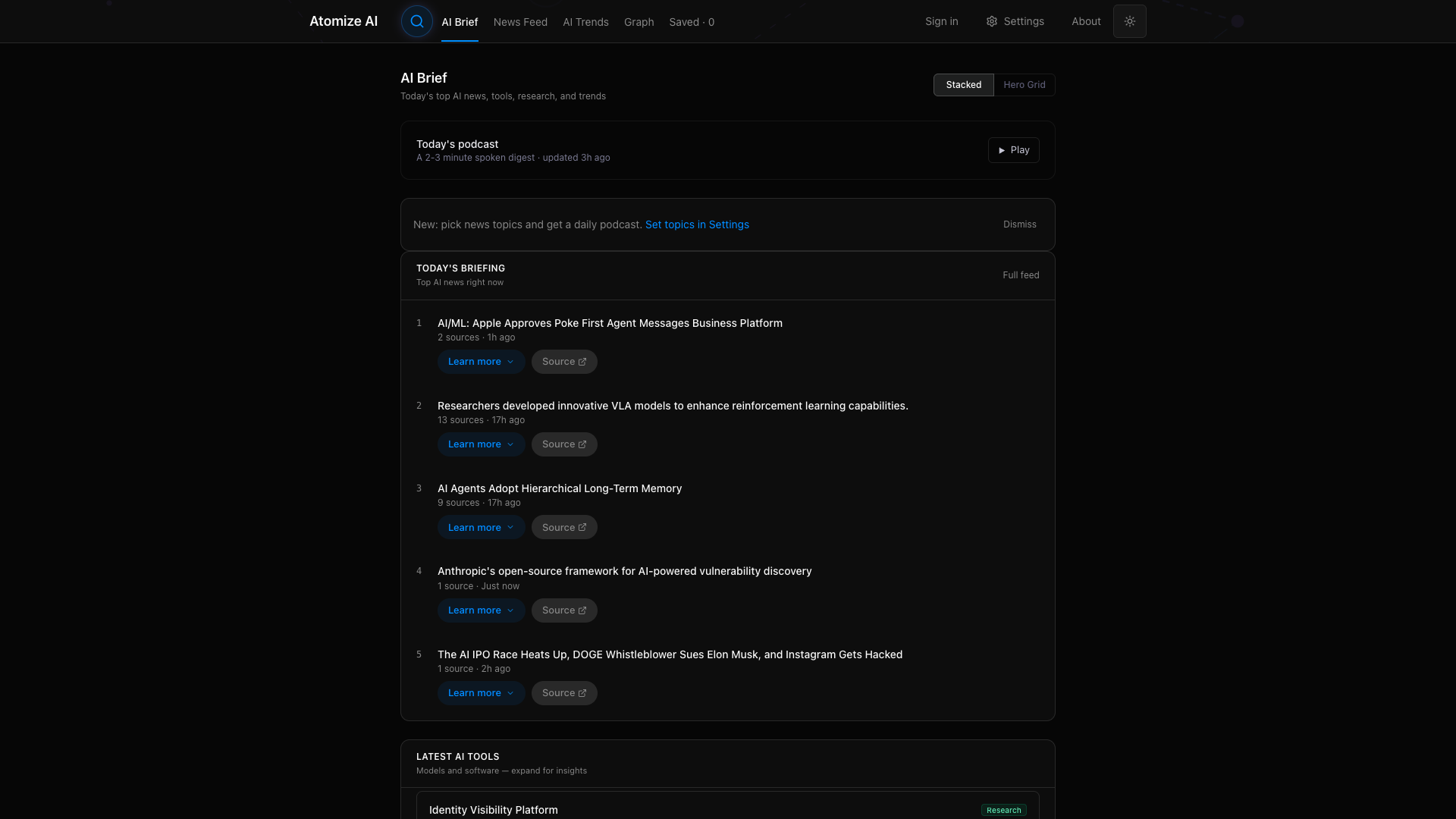
AI Search and Synthesis
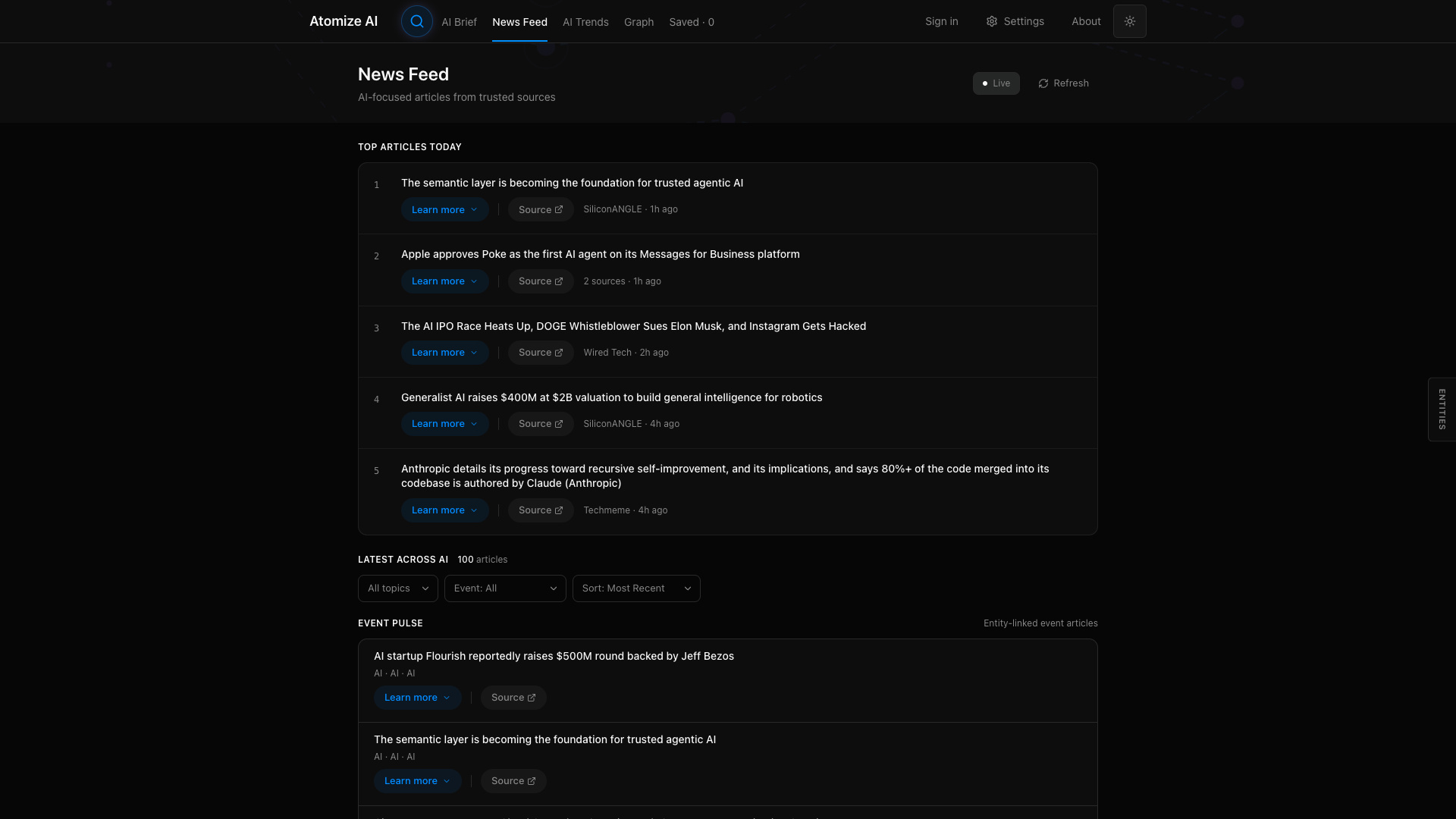
The AI Search mode synthesizes findings across all indexed articles for a given query. A search for “Enterprise AI Adoption” pulls from 50 articles, generates a structured summary with key developments, and cites individual sources with numbered references. Each development links back to the original article for verification. The Simple mode provides traditional keyword search for when you want to browse rather than synthesize.
AI Trends
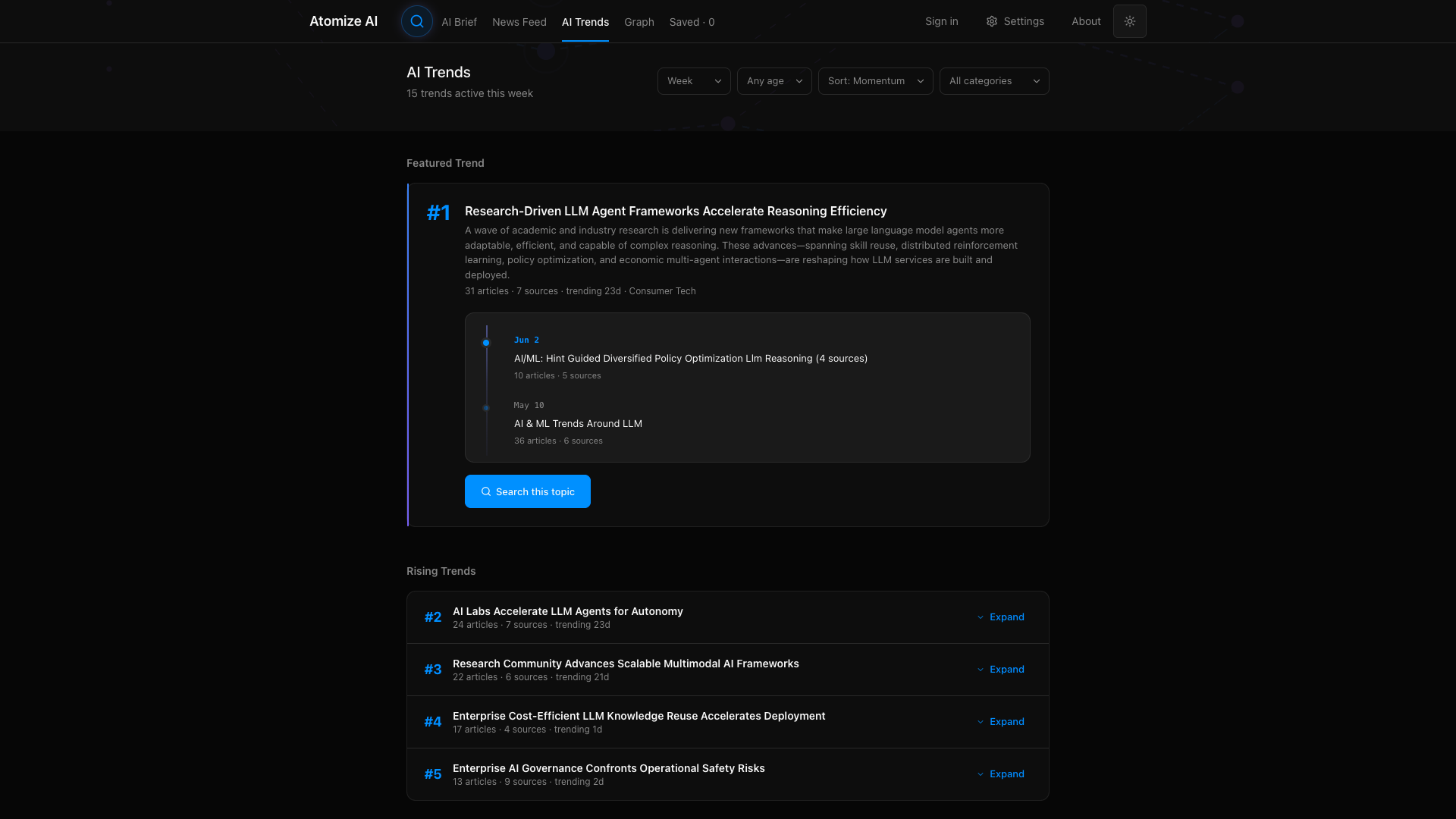
The AI Trends tab surfaces patterns across ingested articles. Trends are scored by momentum, measured by article volume and source diversity over a configurable time window. A featured trend might show “Industry Tightens AI Governance” with 132 articles across 8 sources. Rising trends display as ranked cards with article counts and category tags. Each trend links to a timeline view and topic-specific search, providing both breadth and drill-down capability.
spaCy NLP Microservice for Relationship Verification
The core challenge was entity directionality. LLMs alone can hallucinate relationships or reverse subject-object positions. I deployed a spaCy NLP microservice on Railway ($5/month) that analyzes grammatical dependencies to verify relationship accuracy. It responds in 55ms and solves the “who acquired whom” problem by validating subject-verb-object structures. Verified relationships receive a 20% confidence boost in the knowledge graph, creating a reliable foundation for synthesis.
Entity Classification with Six-Signal Scoring
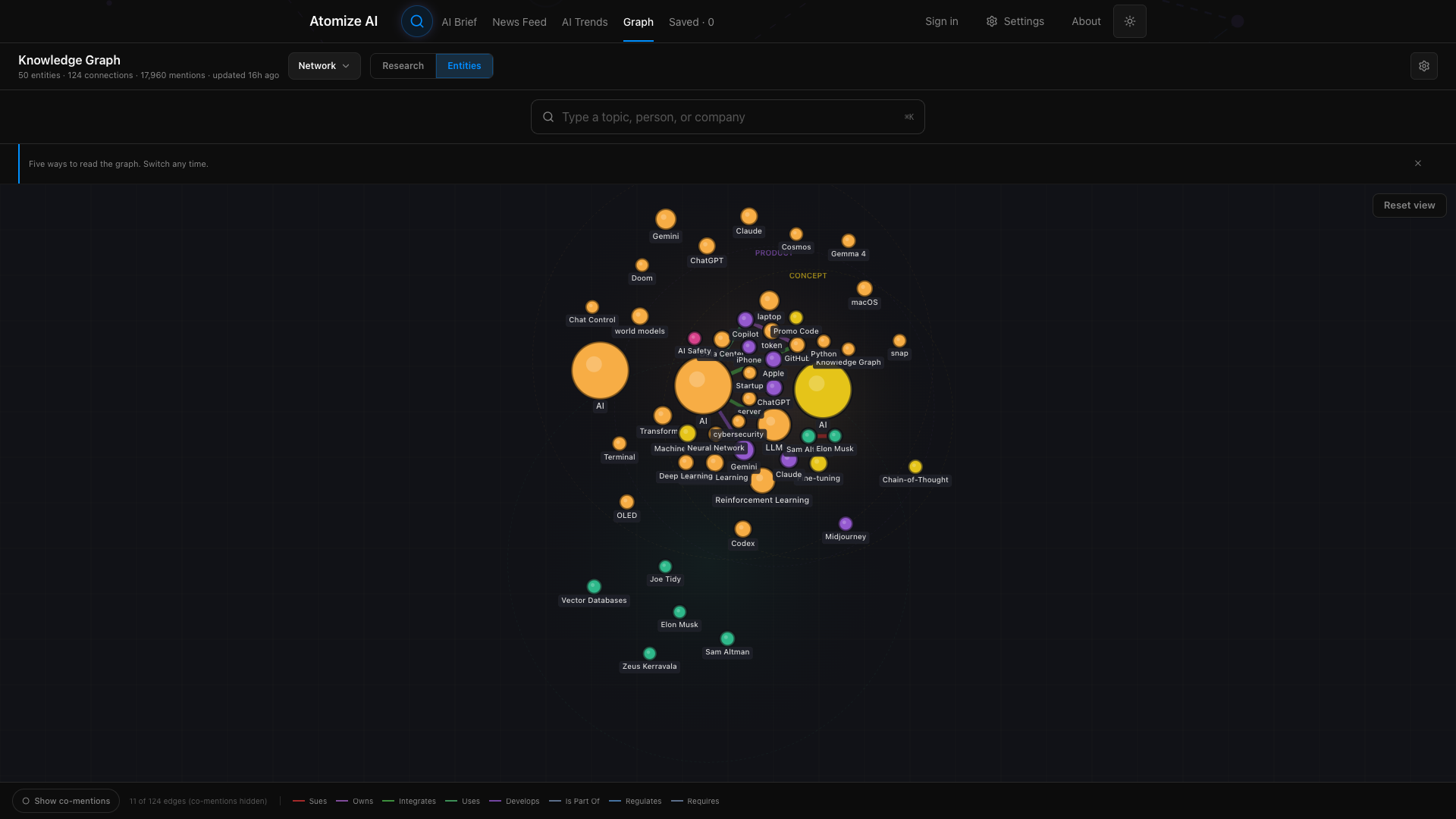
LLM extraction surfaces too much noise — minor people, transient projects, low-relevance organizations get pulled into the graph and dilute every downstream synthesis. I built a six-signal scoring system that scores every extracted entity for inclusion: mention frequency, source-tier diversity, recency-weighted velocity, relationship density in the graph, citation depth in source articles, and an LLM-rated significance score gated by structural checks.
The scoring runs nightly across the corpus. Entities above the threshold pass into the canonical graph; entities below land in an admin review queue where I can promote, reject, or merge them. The first full-corpus run scored 9,556 entities. Roughly 40% landed below the auto-accept threshold and went to review — the queue surfaces the genuinely ambiguous cases, not noise. The promote/reject decisions feed back as labeled data, retraining the threshold weights weekly.
This solves the central problem with LLM-built knowledge graphs: they grow indefinitely. Without a pruning system, the graph drifts toward a soup of every name and concept that ever appeared in any article. The classification gate makes that drift answerable to evidence.
Progressive Pyramid Visualization
Research synthesis needs hierarchical clarity. I implemented a progressive pyramid that layers findings from specific papers (base) to cross-source patterns (middle) to emergent insights (apex). The knowledge graph feeds this structure, with pgvector similarity search connecting related entities across documents. Users navigate from individual papers through thematic clusters to meta-level trends without losing provenance.
Quality Evaluation with LangSmith
I integrated LangSmith with 5 evaluators measuring factuality, coherence, relevance, business impact, and format adherence. Each synthesis run generates scores that guide model selection improvements and prompt refinement. This feedback loop surfaces when the cheaper Groq models suffice versus when OpenAI’s reasoning depth matters. Citation formatting uses [N] markers that expand to [1],[2],[3] references, maintaining academic rigor.
Observability with OpenTelemetry
I instrumented the pipeline with OpenTelemetry and SigNoz for distributed tracing. Every research ingestion, entity extraction, and graph update generates spans showing latency, model selection rationale, and confidence score evolution. This visibility exposes bottlenecks like slow spaCy calls or inefficient vector queries, guiding optimization efforts. Prometheus metrics track cost per synthesis and accuracy trends over time.